
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- SK하이닉스 #SK하이닉스채용 #반도체취업 #AI취업 #시스템아키텍처 #소프트웨어솔루션 #HBM #CXL #LLM #GPU #서버아키텍처 #대학원진학 #이직준비 #취업준비
- 편도수술
- 양양솔비치세프스키친
- 고마워다음
- 아이혼자다녀옴
- 중학교입학수학문제
- 영통외식
- 종이캐리어
- 홍시스무디
- 결항
- 결항전문
- 싱가폴중학교수학문제
- 가족소고기외식
- 파이썬
- 푸르지오포레피스
- 주차넉넉
- 에어아시아
- 양양솔비치조식
- 커피쏟음
- 양양솔비치아침
- 사진문자추출
- 영통역소고기
- 커피
- DFS
- 사진에서 글자추출
- 사진문자추출하기
- python#
- 영통칠프로칠백식당
- 양양솔비치 뷔페
- 당근마켓중고차
- Today
- Total
너와나의 관심사
Densing law of LLMS paper 본문
https://arxiv.org/pdf/2412.04315v1
이제는 num of parmeters 가 아니라 densing of LLM 밀도이다
아래 그림은 chatGPT 출시 이후 밀도가 현재하게 높아짐을 보여준다

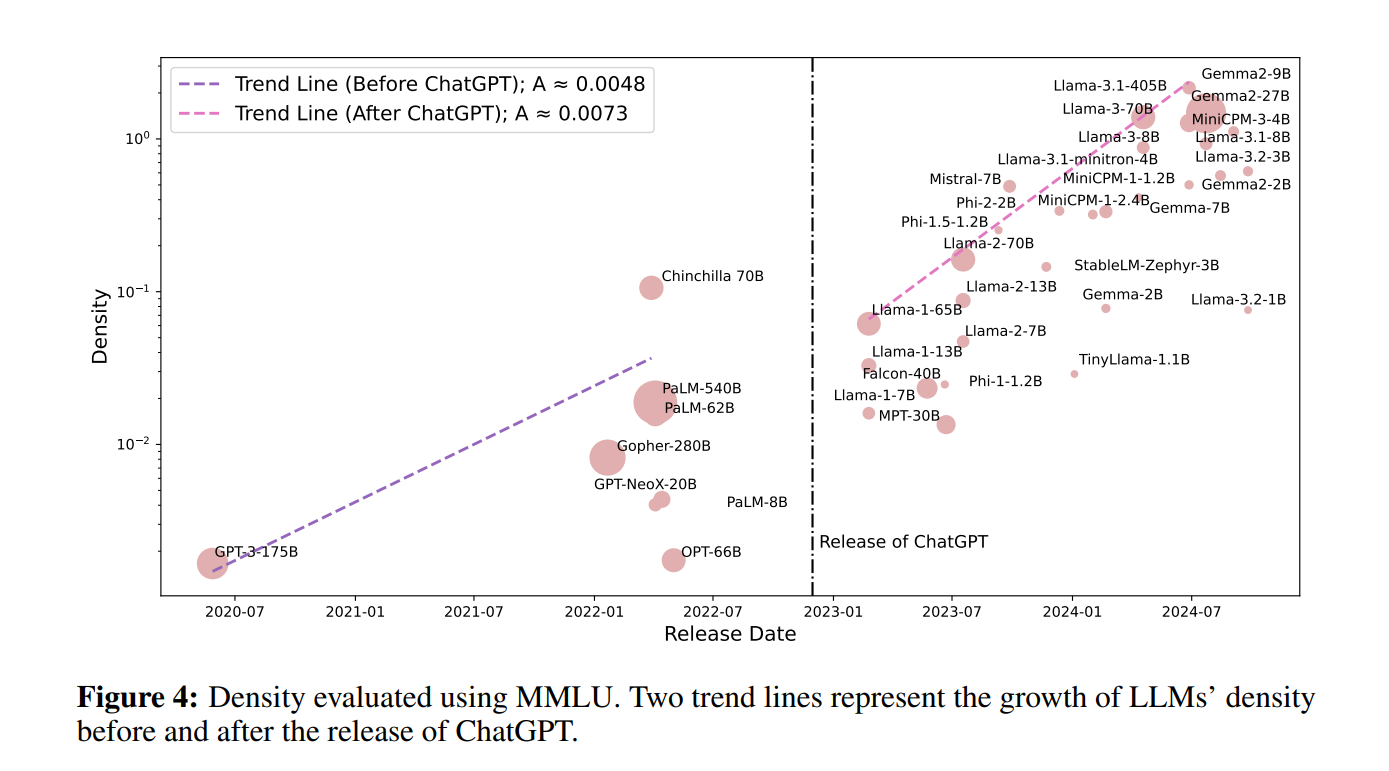

논문의 저자는
Gemma2 9B 만 이전 대비 capacity density 가 높아졌고 이에 반해
최신 llama3.2 1B, 3B 모델의 capacity density 가 낮은 이유로 training 완성도가 떨어져서 llama3.1 8B 보다 학습밀도가 떨어진것으로 보고있다. 이는 task 를 정의하고 충분히 학습한다면 유사한 capasity density 로 따라갈것으로 보고 있다.
1. 개요 (Introduction)
최근 대규모 언어 모델(LLM, Large Language Models)이 AI 연구에서 큰 주목을 받고 있으며, 모델의 성능은 매개변수 및 학습 데이터의 증가에 따라 계속 향상된다는 "Scaling Law"가 입증되었습니다. 그러나, 이러한 모델의 추론 효율성 향상이 점점 더 중요한 과제가 되고 있습니다.
- LLM의 추론 비용이 학습 비용을 초과하면서 실용적 문제로 대두됨
- 스마트폰과 같은 리소스가 제한된 환경에서도 LLM을 사용할 필요성이 증가
- LLM의 "Inference Scaling Law"는 추론 단계에서 더 많은 토큰을 생성할수록 성능이 향상됨을 시사
이러한 도전에 대응하기 위해 저자들은 **"Capacity Density"**라는 개념을 도입하여 LLM의 훈련 품질을 평가하는 새로운 방법을 제안합니다.
2. 주요 연구 결과 (Key Findings)
저자들은 최근 몇 년간 공개된 29개의 대표적인 LLM을 분석하여 다음과 같은 법칙을 발견하였습니다.
- Densing Law (밀집 법칙)
- LLM의 "Capacity Density(밀집도)"는 시간이 지남에 따라 지수적으로 증가
- 즉, 모델의 밀집도가 약 3개월마다 2배씩 증가
- 같은 성능을 내는 모델이 기존보다 절반의 매개변수로도 가능해짐
- 추론 비용의 급격한 감소
- 같은 성능을 내는 모델을 점점 작은 크기로 만들 수 있어, 추론 비용이 지수적으로 감소
- 예를 들어, 2023년 1월부터 현재까지 GPT-3.5 수준의 모델 추론 비용은 266.7배 감소
- Densing Law와 Moore’s Law의 결합
- Moore의 법칙(반도체 집적도가 18~24개월마다 2배 증가)과 결합될 경우,
동일한 가격의 칩에서 실행할 수 있는 LLM의 실제 매개변수 크기가 더 빠르게 증가
- Moore의 법칙(반도체 집적도가 18~24개월마다 2배 증가)과 결합될 경우,
- ChatGPT 이후 밀집도 성장 가속화
- ChatGPT 출시 이후 LLM 밀집도 증가율이 50% 빨라짐
- 이는 LLM 연구 및 최적화가 빠르게 발전하고 있음을 시사
3. 모델 평가 방법 (Evaluation)
LLM의 밀집도를 평가하기 위해 다음 과정을 거쳤습니다.
- 손실 추정 (Loss Estimation)
- 다양한 크기의 모델을 학습시켜 손실 함수를 기반으로 성능을 예측
- 성능 추정 (Performance Estimation)
- 기존 모델 및 새로 학습한 모델을 사용하여 성능-손실 곡선을 추정
- 밀집도 계산 (Density Calculation)
- 위 데이터를 이용해 모델의 상대적 밀집도를 정량적으로 평가.
4. 결론 (Conclusion)
- LLM의 밀집도가 3개월마다 2배씩 증가하는 경향을 보이며, 같은 성능을 내는 데 필요한 모델 크기가 점점 줄어듦
- 추론 비용 또한 빠르게 감소하여, 고품질 LLM을 저비용으로 운영할 수 있는 시대가 가까워짐
- 연구진은 이러한 법칙이 미래 LLM 연구 방향을 제시하고, 최적의 성능을 최소한의 계산 비용으로 달성할 수 있도록 기여하기를 기대.
이 논문은 LLM의 효율적인 확장을 위한 새로운 법칙을 제안하고, 추론 비용 감소의 중요성을 강조합니다. 빠르게 변화하는 LLM 생태계에서 밀집 법칙(Densing Law)이 앞으로 중요한 연구 주제가 될 가능성이 큽니다.